En un proyecto de Business Intelligence es muy común tener tablas con millones de registros para la creación de consultas y reportes. Para esta situación, tenemos dos alternativas.
- Optimizar la gestión de la consulta en base de datos relacionales
- Cambiar a una base de datos basado en columnas.
Para entender la necesidad en nuestro proyecto debemos identificar lo siguiente:
- En BI normalmente se inicia con una tabla colectora de datos donde guardamos los datos en un esquema copo de nieve donde agrupamos los datos por la fecha. Esta tabla puede llegar a ser muy grande ya que almacenará todos los registros que soportaremos en el modelo y las operaciones que vamos a querer realizar sobre esta tabla son:
- Consulta: Lo mejor es que esta consulta SQL sea grabada en una vista materializada para acelerar el tiempo de respuesta
- Archivar registros: Los datos no se mantienen en la tabla para siempre, se tiene que fijar una antigüedad máxima para moverlos fuera a otro almacenamiento mas barato. Se debe poder quitar datos antiguos y cargarlos en otro motor o simplemente tenerlos archivarlos.
Volviendo a nuestras opciones: para la primera opción, dentro del rango de las bases de datos relacionales, tenemos una opción definitiva que son las Vistas Materializadas. Con esta opción, vamos a poder grabar la estructura de la consulta en una tabla, donde podremos crear índices, acelerando dramáticamente la velocidad de respuesta. Además, a fin de gestionar mejor el acceso a los datos, se suele utilizar particionamiento que consiste en agrupar datos en archivos de tablespace de tal manera que los archivos que tenga que leer la base de datos sean mas pequeños. En proyectos de BI normalmente la partición se hace con la fecha, por lo general un archivo por día.
Si estuviéramos trabajando con Oracle, la solución estaría lista pues cuentan con la funcionalidad de crear vistas materializadas que pueden ser particionadas, y además, se pueden ir refrescando en forma diferencial, lo que hace todo muy simple. Pero este no es el caso pues Oracle cuesta (Aunque la versión Express es una buena opción para proyectos pequeños).
En PostgreSQL tenemos estas opciones:
- Tablas particionadas: si es posible crear una tabla con particiones por día. La creación de las particiones es declarativa, lo que significa que debemos ir creando las tablas de partición en forma manual
- Vistas Materializadas: también soporta la opción de crear una tabla basada en una consulta SQL y también ofrece la opción de refrescar PERO el refresco es total, por lo que no es conveniente refrescar una vista materializada si sabemos que tiene demasiados registros. Lamentablemente, las vistas materializadas no soportan particiones. Otro punto en contra es que las vistas materializadas no se pueden consultar mientras se refrescan, pero esto se puede solucionar creando una llave primaria en la vista y ejecutar el refresco en modo “concurrente”.
Con estas dos funciones, deberíamos implementar una funcionalidad como sigue:
- Una tabla de ingreso que llamaremos RAW que estará particionada por día
- Una tabla de configuración CONFIG donde definiremos:
- La fecha minima de los registros que nos sirve para actualizar los datos nuevos. No se puede usar CURRENT_DATE porque no nos permitiría refrescar la última vista al término del día pues si se pasa al día siguiente, no podríamos asegurar que se incluyan todos los registros del día anterior porque no se sabe el tiempo que tomará actualizar la vista. Por eso, fijamos este valor en la tabla: la fecha mínima de los únicos datos que vamos a refrescar.
- la cantidad de días de información que queremos tener en las vistas materializadas
- En una vista materializada tendremos grabada los resultados de la consulta PERO CON LAS SIGUIENTES CARACTERÍSTICAS:
- Definiremos una cantidad de vistas materializadas que se refrescarán una por periodo
- El periodo es la cantidad de días que hemos definido en la tabla CONFIG dividido entre la cantidad de vistas materializadas
- Para decidir que vista materializada refrescar, tomaremos la diferencia de días que hay desde la fecha actual a la fecha ini definida y la dividimos entre el periodo. El resultado entero estará en el rango de 1 a N donde N es la cantidad de vistas materializadas. Con esta lógica en un día siempre refrescaremos una misma vista materializada
- Finalmente, todas las vistas materializadas se agrupan dentro de una vista normal en una consulta Select UNION.
- Todo esto se gestiona automáticamente mediante un procedimiento que se ejecuta diariamente con PG_CRON
- Ahora, esa fecha la tendremos que actualizar cuando el rando de días entre la fecha actual y la fecha ini sea igual o mayor a 120. En ese momento fijaremos FechaINI = a CURRENT_DATE y comenzaremos a refrescar desde la primera vista.
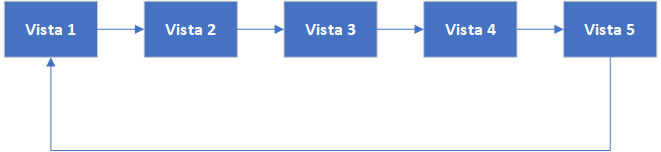
- Para darnos una idea, estamos usando las vistas materializadas como cajas para almacenar registros, cuando llenemos la última caja, volvemos a la primera caja para llenarla con los registros mas recientes, quitando los registros mas antiguos. Algo así:

Finalmente, vamos a crear una vista regular con una consulta Select Union que agrupará todas estas vistas materializadas. Lo veremos mas adelante donde usaremos los comandos de cada objeto.
De esta manera tendremos:
- Todos nuestros datos para el periodo que hemos definido divididos en varias vistas materializadas. En otras palabras, hemos logrado tener particiones.
- En lugar de refrescar toda la vista, mediante la lógica solamente haremos el refresco del último periodo solamente, mientras que la información más antigua es simplemente mantenida.
- Finalmente, como podremos hacer un seguimiento del tamaño de cada una de las vistas, podremos hacer una estimación del tamaño total que necesitaremos por lo que podremos dedicar un tablespace exclusivo y planificar nuestras necesidades de espacio.
Ahora veamos todo esto ya con código.
Tabla de entrada:RAW
Esta es la tabla donde se registran todos los datos que se extraen del modelo transaccional hacia nuestro modelo de BI, por lo que esperamos una gran cantidad de registros así que la debemos tener particionada:
CREATE TABLE meta.RAW (
fecha timestamp NULL,
minuto numeric NULL,
ip varchar NULL,
hostname varchar NULL,
entidad varchar NULL,
grupo varchar NULL,
tipo varchar NULL,
valor numeric NULL
)
PARTITION BY RANGE (date_trunc('day'::text, fecha))
TABLESPACE pgdatain;
En esta tabla se agrega la opción PARTITION donde se le indica que el rango es la fecha truncada para que no tenga información de la hora, sólo el día. Entonces cada día podrá tener una tabla que se podrá gestionar como una tabla independiente. Dije “podría” porque aún falta crear las particiones. Antes, no te olvides de crear los índices que serán heredados a las particiones.
CREATE TABLE meta.RAW_20230306 PARTITION OF meta.RAW FOR VALUES FROM ('2023-03-06 00:00:00') TO ('2023-03-07 00:00:00');
Esta es una partición que puede almacenar datos para el 6 de marzo del 2023. El límite superior es como si fuera un “<” mientras que el límite inferior es como un “>=”. Ahora, el problema con esto es que si queremos almacenar otras fechas habría que crear otra tabla con el rango adecuado. Entonces debemos tener la precaución de crear las tablas con anticipación. Mejor aún, podemos tener un CRON JOB que se ejecute muy tarde y cree la partición para el día siguiente.
La ventaja inmediata es que la vista de la tabla particionada es así: 
Vista Materializada
Aquí viene lo trabajoso. Primero hay que definir una tabla de configuración:
CREATE TABLE public.config_partition (
id numeric NOT NULL,
entidad varchar NULL,
fechaini date NOT NULL,
plazo numeric NOT NULL,
CONSTRAINT config_partition_pk PRIMARY KEY (id)
);
CREATE UNIQUE INDEX config_partition_entidad_idx ON public.config_partition USING btree (entidad);
Aquí creamos esa tabla, donde tenemos:
- Entidad -> que nos permite tener varias vistas materializadas controladas en la misma tabla
- Fechaini -> indica la fecha mínima que tendrán los registros que se refrescarán en la vista
La cantidad de vistas es algo que debemos gestionar en forma manual, porque no hay como crear las vistas en forma dinámica. Si queremos 10, creamos 10 y si queremos mas, creamos mas. La clave es encontrar la cantidad máxima de registros que se pueden tener en un periodo sin afectar demasiado el tiempo de respuesta.
El periodo no lo tenemos aquí pero se calcula al vuelo para eso debemos definir unas funciones para ayudarnos a definir las condiciones en las vistas:
- getpartfini(entidad) -> que nos devuelve la fecha-ini para la entidad (o tabla de entrada) que queremos
- getparttot(entidad) -> que nos devuelve el plazo o cantidad de días que mantendremos en las vistas materializadas
- getpartfechainiorden(entidad, orden,total) -> que nos devuelve la fecha mínima que debemos indicar en la condición de la vista “orden” considerando que hemos creado “total” vistas materializadas.
- getpartfechafinorden(entidad,orden,total) -> que nos devuelve la fecha máxima que debemos indicar en la condición de la vista “orden” considerando que hemos creado “total” vistas materializadas.
Si las ponemos en código:
CREATE OR REPLACE FUNCTION public.getpartfini(entidad character varying)
RETURNS date
LANGUAGE sql
IMMUTABLE PARALLEL SAFE AS $function$
select fechaini from config_partition where entidad=entidad;
$function$;
CREATE OR REPLACE FUNCTION public.gerparttot(entidad character varying)
RETURNS integer
LANGUAGE sql
IMMUTABLE PARALLEL SAFE AS $function$
select plazo from public.config_partition where entidad = entidad;
$function$;
CREATE OR REPLACE FUNCTION public.getpartfechainiorden(entidad character varying, orden integer, total integer)
RETURNS date
LANGUAGE plpgsql
IMMUTABLE PARALLEL SAFE AS $function$
declare
fini date;
plazo integer;
begin
fini = getpartfini(entidad);
plazo = getparttot(entidad)/total;
return fini + (orden-1) * plazo * '1 day'::interval;
end;
$function$;
CREATE OR REPLACE FUNCTION public.getpartfechafinorden(entidad character varying, orden integer, total integer)
RETURNS date
LANGUAGE plpgsql
IMMUTABLE PARALLEL SAFE AS $function$
declare
fini date;
plazo integer;
begin
fini = getpartfini(entidad);
plazo = getparttot(entidad)/total;
return fini + (orden) * plazo * '1 day'::interval;
END;
$function$;
Ahora definamos el controlador de vistas. Para eso, definimos una función controlador por cada entidad. Digamos que esa entidad se llama “interface”.
CREATE OR REPLACE PROCEDURE public.upddateinterface()
LANGUAGE plpgsql AS $procedure$
declare
diff integer;
begin
select (current_date - getpartfini('interface'))/10 +1 into diff;
if diff>=getparttot('interface') then
refresh materialized view concurrently mvw_interfacetotal12;
update public.config_partition set fecha_ini = current_date where entidad='interface';
end if;
END;
$procedure$;
Ahora veamos la plantilla para las vistas materializadas:
Este procedimiento debe ejecutarse en la primera hora del día siguiente que queremos refrescar. Por ejemplo, cuando este procedimiento se ejecute a las 01:00 del día 15, estará terminando de incluir en la vista materializada todos los registros correspondientes del día 14, como veremos en un momento mas al definir la vista materializada.
CREATE MATERIALIZED VIEW public.mvw_interfacetotal01
TABLESPACE pgdata AS
SELECT inter.fecha,inter.ip,inter.hostname,inter.entidad,
CASE WHEN inter.tipo::text = '1'::text THEN inter.valor ELSE 0::numeric END AS bandwidth,
CASE WHEN inter.tipo::text = '2'::text THEN inter.valor ELSE 0::numeric END AS bitsin,
CASE WHEN inter.tipo::text = '3'::text THEN inter.valor ELSE 0::numeric END AS bitsout,
CASE WHEN inter.tipo::text = '4'::text THEN inter.valor ELSE 0::numeric END AS packsin,
CASE WHEN inter.tipo::text = '5'::text THEN inter.valor ELSE 0::numeric END AS packsout
FROM meta.interfaceraw1 inter
WHERE inter.fecha < getpartfechafinorden('interface'::character varying, 1, 12) AND inter.fecha >= getpartfechainiorden('interface'::character varying, 1, 12)
Aquí podemos ver la creación de la primera vista, las siguientes serán similares cambiando solamente el índice en el nombre y en la condición que hay en el Where. Si nos fijamos, para el límite inferior usamos la función que definimos mas arriba indicando la entidad “interface”, 1 porque corresponde a la vista 1 y 12 porque son un total de 12 vistas donde iremos distribuyendo los datos. Lo mismo para definir el límite superior pero usando la otra función. Con un poco de imaginación tendremos 12 vistas materializadas similar a esta creadas en nuestra base que manejaremos como una sola mediante una vista regular tal como sigue:
CREATE OR REPLACE VIEW public.mmvw_interfacetotal AS
SELECT mvw_interfacetotal01.fecha,mvw_interfacetotal01.fechafiltro,mvw_interfacetotal01.ip,
mvw_interfacetotal01.hostname,mvw_interfacetotal01.entidad,mvw_interfacetotal01.bandwidth,
mvw_interfacetotal01.bitsin,mvw_interfacetotal01.bitsout,mvw_interfacetotal01.packsin,
mvw_interfacetotal01.packsout FROM mvw_interfacetotal01
UNION
SELECT mvw_interfacetotal02.fecha,mvw_interfacetotal02.fechafiltro,mvw_interfacetotal02.ip, mvw_interfacetotal02.hostname,mvw_interfacetotal02.entidad,mvw_interfacetotal02.bandwidth, mvw_interfacetotal02.bitsin,mvw_interfacetotal02.bitsout,mvw_interfacetotal02.packsin,
mvw_interfacetotal02.packsout FROM mvw_interfacetotal02
UNION
SELECT mvw_interfacetotal03.fecha,mvw_interfacetotal03.fechafiltro,mvw_interfacetotal03.ip,
mvw_interfacetotal03.hostname,mvw_interfacetotal03.entidad,mvw_interfacetotal03.bandwidth, mvw_interfacetotal03.bitsin,mvw_interfacetotal03.bitsout,mvw_interfacetotal03.packsin,
mvw_interfacetotal03.packsout FROM mvw_interfacetotal03
UNION
------
Con esto ya tendremos una vista materializada y particionada donde podremos ir refrescando los datos por partes sin afectar el rendimiento de las consultas y sobre todo, controlando el uso del disco.
Ventajas
Todo este trabajo nos dará la primera gran ventaja: Mejora en el tiempo de respuesta del reporte o consulta. Esto se cumple principalmente por la partición basada en la fecha y que es justamente uno de los parámetros que se utilizan en los reportes y consultas en BI, esto permite que no se carguen las particiones que no se usan. El tiempo de respuesta se mantiene así tengamos todas las vistas materializadas llenas.
Lo siguiente es la carga en el refresco. Si tenemos una vista que puede tener digamos 24 millones de registros, pasarlas a una vista materializada tomará un tiempo considerable, por lo que no nos queda mas que refrescar solamente un periodo menor a fin de que nuestros reportes muestren datos nuevos cada 20 a 30 minutos en lugar de tener reportes atrasados 1 día o dos.
Y finalmente, la gestión de almacenamiento se mejora:
- En la tabla de captura RAW, cada tabla de partición es independiente, por lo tanto, podremos ir moviendo las particiones mas antiguas a discos mas baratos o simplemente archivarlos. En el primer caso, la consulta a esos datos será mas lenta pero estarán en línea, mientras que en el segundo caso, se tendrá que poner un sistema alterno para la consulta.
- En las tablas materializadas, el almacenamiento tendrá un valor máximo fijo y el movimiento de los archivos también se reducirá a un archivo por periodo mejorando el rendimiento del disco.
Lo mejor que plantea esta alternativa es que sirve tanto para pocos registros como para millones que es donde notaremos realmente las ventajas, pero el costo de la implementación es muy bajo pues las particiones generan muy poca congestión, y el refresco de las vistas materializadas es concurrente y limitado a un periodo.
Con esto ya pueden utilizar a PostgresSQL como su base de datos de reportes para sus proyectos de BI.
Mencioné al inicio que había otra alternativa y que era migrar a una base de datos por columnas y para eso debo recomendar Clickhouse que ya he utilizado y que permite entre otras cosas:
- Particionar los datos en forma automática
- Comprimir los datos
- Al ser basado en columnas, se puede consultar por cualquiera de ellas ya que todas estarán indexadas
- Optimiza el uso de la memoria
- Y sobre todo, tiene un tiempo de respuesta que es increíblemente bajo a pesar de manejar millones de registros
Dedicaré otro post a describir como se utiliza y las ventajas de Clickhouse





Leave a comment